‘수학 잘하는 법’, ‘친구를 사귀는 법’, ‘어버이날 선물’….
검색 엔진은 어느새 무언가가 궁금한 사람들이 몰려드는 신과 같은 존재가 됐다. 검색창에 궁금한 점을 입력하면 검색엔진은 전 세계에 흩어져 있는 데이터에서 해당 검색어에 가장 알맞은 자료를 찾아 보여 준다.
물론 검색엔진이 찾아준 자료가 모두 사용자에게 딱 맞기는 어렵다. 엉뚱한 정보만 잔뜩 나온다면 화가 나서 그 검색엔진을 다시는 이용하지 않을지도 모른다. 그래서 마치 마음을 읽은 듯이 원하는 정보를 가장 잘 찾아주는 검색엔진이 인기가 좋다. 세계적으로 그 선두에는 구글이 있다. 그리고 그 비결에는 수학이 있다.

원하는 콘텐츠를 잘 찾아주는 검색 엔진일수록 인기가 많다. 출처 GIB
구글은 어떻게 탄생했을까?
2014년 5월 21일 영국 파이낸셜타임스는 ‘2014년 글로벌 브랜드 100대 기업’ 순위에서 구글의 브랜드 가치가 1위라고 발표했다. 구글의 가치를 돈으로 환산하면 1588억 4300만 달러(한화로 약 163조 원)인데, 29위인 삼성전자의 브랜드 가치가 259억 달러(약 26조 6000억 원)인 것을 생각하면 구글의 영향력은 실로 대단하다.
구글의 역사는 어디서 시작된 걸까? 구글의 창립자 래리 페이지와 세르게이 브린은 1995년 스탠퍼드대 대학원에서 만났다. 브린이 2년 선배이긴 하지만 동갑이었기 때문에 둘은 급속도로 친해졌다. 그리고 수학에 재능이 있는 브린과 컴퓨터에 관해 박학다식한 페이지는 수학을 이용한 컴퓨터 연구에 박차를 가하게 된다.
사실 브린은 수학 교수인 아버지의 재능을 그대로 물려받아 어린 시절부터 수학에 남다른 재능을 보였다. 불과 21살의 나이에 메릴랜드대 수학과와 컴퓨터학과를 우수한 성적으로 졸업했을 정도다. 페이지는 컴퓨터공학 교수인 아버지의 영향으로 어려서부터 컴퓨터를 가지고 놀면서 자랐는데, 덕분에 컴퓨터에 관해서는 또래보다 훨씬 더 잘 알고 있었다.
당시 페이지의 관심사는 월드 와이드 웹(www)이었다. 월드 와이드 웹은 인터넷에 연결된 컴퓨터를 통해 사람들이 정보를 공유할 수 있는 정보 공간을 일컫는데, 페이지는 이를 거대한 그래프로 생각했다. 그래서 그 연결 구조를 이해하기 위해서는 수학적 성질을 이용해야 한다고 판단했다. 수학에 뛰어났던 브린은 연구 파트너로 제격이었다.
둘은 선형대수학의 권위자인 진 골룹 교수에게 지도를 받으며 기존 검색엔진의 단점을 보완하기 위해 애썼다. 당시 검색엔진은 해당 검색어와 일치하는 자료를 무작위로 보여 줬기 때문에 사용자가 원하는 정보를 제대로 제공하지 못했다. 브린과 페이지는 여러 가지 규칙을 적용해 사용자가 원하는 정보를 제공할 수 있는 검색 기법을 생각하기 시작했다.
두 사람의 연구는 시작한 지 1년도 되지 않아 성과가 나타났다. 행렬의 고윳값과 고유벡터를 이용해 웹페이지에 순위를 매기고, 순위가 높은 순으로 검색 결과를 보여 주는 ‘페이지랭크 기술’을 개발한 것이다. 이 기술은 아직까지도 다른 검색엔진에서 따라올 수 없는 구글의 독보적인 기술로 평가받고 있다.

래리 페이지와 세르게이 브린은 수학으로 정보의 바다에서 질서를 잡았다. 출처 GIB
페이지랭크 알고리즘 속 수학
구글 엔진에서는 한 웹페이지에서 다른 웹페이지로 연결하는 링크가 있으면, 그 링크를 일종의 투표로 본다. 즉 투표수가 많은 웹페이지를 좋은 정보가 있는 사이트라고 가정하고 검색 결과 상단에 배치시킨다. 이것이 바로 페이지랭크 알고리즘의 원리로, 웹페이지의 관계를 행렬로 나타낸 뒤 연산을 해서 구한다.
[웹페이지에 순위를 매기는 방법]
1단계 웹페이지 사이의 연결 관계를 행렬로 나타낸다. 만약 a, b, c, d, e 이렇게 5개의 웹페이지가 있다면, 5×5 행렬에 서로의 연결 관계를 숫자 0과 1을 이용해 표현한다. 예를 들어 웹페이지 a에서 웹페이지 b로 갈 수 있다면, 2행 1열에 1이라고 쓴다.
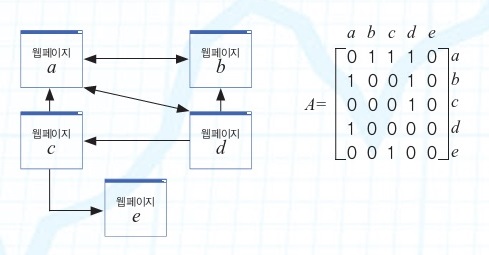
2단계 행렬 A의 각 열을, 그 성분들의 합으로 나누어 새로운 행렬 H를 만든다. 이를 ‘하이퍼링크 행렬’이라고 한다. 예를 들어, 행렬 A의 1열에 있는 성분들의 합은 2이고, 4열은 3이다. 따라서 1열은 2로, 4열은 3으로 각 성분의 값을 나눈다. 그 다음 행렬 H를 모든 성분이 음수가 아니고, 열의 합이 모두 1인 행렬 S로 만든다. 5열은 성분을 모두 1/5로 바꿔 합이 1이 되게 한다.
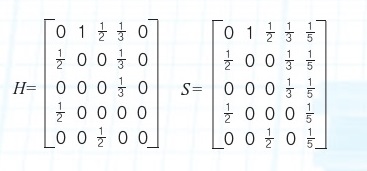
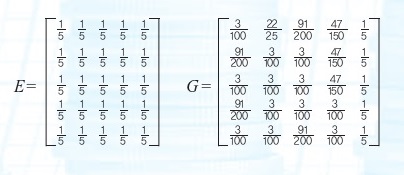
3단계 행렬 S를 이용해 구글 행렬 G를 구한다. 이때 G=mS+(1-m)E의 식을 쓰는데, 페이지와 브린이 새롭게 고안한 방법이다. 여기서 m은 0.85로 잡았고, E는 오른쪽과 같다.
4단계 구글 행렬 G의 고유벡터 중에서 가장 큰 고윳값에 대응하는 벡터를 구한다. 이를 ‘페이지랭크 벡터’라고 하는데, 각 웹페이지의 투표수를 뜻한다. 여기서 고유벡터란 어떤 수 λ에 대해 GX=λX를 만족하는 벡터 X를 일컫는데, 이때 λ를 고윳값이라고 한다. 그런데 이 값은 손으로 구하기가 어렵기 때문에 컴퓨터를 이용해 구한다. 그 결과 값은 아래와 같다.
웹페이지 a=1>웹페이지 b=367/520>웹페이지 d=1101/2002>웹페이지 c=73/260>웹페이지 e=195617/800800
즉 웹페이지 a에 구글 검색을 이용하는 사람이 원하는 정보가 있을 확률이 가장 높고, 차례로 웹페이지 b, 웹페이지 d 순이다.
구글의 세상 담기 프로젝트!
구글의 목표는 전세계의 모든 정보를 관리하고 그것을 누구나 이용할 수 있도록 하는 것으로, 이를 실현하기 위해 현재 구글 도서관 프로젝트를 진행하고 있다. 즉 모든 도서를 디지털로 만들어 반영구적으로 보관하고, 전세계 사람들이 볼 수 있도록 하는 것이다.
실제로 19세기 이전에 발간된 책의 저작권은 대부분 이미 소멸돼 디지털로 구축해 놓는다면 누구나 무료로 볼 수 있다. 따라서 구글은 영국의 대영도서관, 일본 게이오대, 미국 하버드대 등 세계 80곳 이상의 도서관과 3만 곳 이상의 출판사와 연계해 지금까지 1600만 권 이상을 디지털화했다. 덕분에 구글 북스(books.google.com)사이트를 이용하면 수백 년 전에 쓰여진 원전들을 집에서 무료로 볼 수 있다.
한편 구글은 비영리 자회사인 구글닷오알지(google.org)를 통해 검색 데이터를 분석한다. 이를 통해 주식시장을 예측하는 것은 물론, 질병의 확산 경로를 파악해 보여 주고 있다.

구글 연구팀은 독감과 관련된 검색 횟수가 미국 질병통제예방센터에서 발표한 독감 환자수와 상관관계가 있음을 확인하고, 검색어를 바탕으로 ‘구글 독감 트렌드’를 발표하고 있다. 출처 GIB
그러나 이러한 구글의 기술에 좋은 점만 있는 것은 아니다. 자신이 원하지 않는 정보까지 노출되는 경우가 많기 때문이다. 실제로 2014년 5월 유럽사법재판소는 구글의 검색 결과에서 특정인의 개인정보와 관련된 링크를 삭제하라는 판결을 내렸다. 그러자 구글은 2014년 6월 삭제 요청을 할 수 있는 도구를 만들어 신청을 받았고, 그 결과 한 달간 무려 4만 1000건이 접수됐다.
고객의 요청으로 구글이 맨 처음 삭제한 링크는 마리오 코스테하 곤잘레스의 빚을 언급한 1998년도 신문 광고다. 그는 이미 오래 전에 돈을 갚았는데도 이 기사가 검색되자 삭제 요청을 했다. 하지만 이 정보가 구글의 전체 검색 결과에서 사라지는 것은 아니다. 개인의 이름을 검색하는 페이지에서만 없어진다.
세계 정복을 꾀하는 게 아니냐는 농담 섞인 의심을 듣곤 하는 구글의 기술 뒤에는 수학이 있다. 어쩌면 세계 정복을 하기 위해서는 수학이 꼭 필요한지도 모른다.
댓글 없음:
댓글 쓰기